Tutorial: the k.LAB resources layer
1. Introduction
Resources are used in k.LAB to make observations - finished scientific artifacts that describe a concept. This process involves:
-
the choice of a context for the observation (for example, a spatial region and a time period, at user-specified extents and resolution), and
-
a logical query (e.g. a concept, such as
geography:Elevation) which is resolved to one or more semantic models, producing a computational strategy that ultimately relies on resources to provide or compute data.
This document describes the Resources layer, i.e. the bottom layer of three in the k.LAB architecture, in which we find what is easily identified as "conventional" in the world of knowledge artifacts: datasets or data services, devoid of semantics beyond metadata.
Importantly, in k.LAB, computations, from simple equations to complex models, can also live in the resources layer. In fact, anything that takes inputs and produces outputs in numeric or other form, with no meaning explicitly attached beyond names and metadata, can be seen as a k.LAB resource. Inputs and outputs will be similarly identified by a name and a type, for example numbers or textual categories. Imagine this as a black & white world, where the "standard" products of scientific research can live safely for a long time.
In the semantic layer of k.LAB, resources are coupled with concepts, creating an integrated world of knowledge that the resources layer alone can’t provide. This is where the world gets its meaning - its colors! - and where integration becomes possible. In the resources layer, knowledge is only identified by names and basic types, such as numeric, textual, or boolean, and only basic validation of compatibility between resources is possible.
The aim of the resources layer is offering a common interface for k.LAB to access and manage pre-existing data, models and services of all kinds, as a first level of interoperability.
| While the semantic layer specifies a language for interoperability, the resource layer provides a protocol. |
The resource layer protocol is implemented as a simple, carefully designed API, enabled through the use of adapters, i.e. software plug-ins that adapt a specific data or service format to the API. Adapters are made available as k.LAB components, installable in k.LAB Engines and k.LAB Nodes, and can be extended by developers using the Java API to support formats and services not yet available.
This document looks at resources handling in a learn-by-example fashion, from two different angles:
-
the modeler perspective: using k.Modeler to create, modify, test, access or delete resources;
-
the developer perspective: the Java API and classes used to manage resources in the k.LAB Engine.
This document assumes that the reader is already acquainted with k.Modeler’s user interface and its k.LAB perspective.
1.1. Example project
In the following sections an example project named im.docexample is used, which has been created using the default parameters of the project creation wizard.
Each k.LAB project contains a resources node in its tree:

Adding a file resource (ex. an ESRI shapefile, CSV file, or geotiff raster coverage) is as simple as dragging a file from the filesystem explorer to the resources node.
Let’s for example add a Natural Earth world shapefile to the example resources by dragging it onto the Resources tree node. The resource is instantly imported and appears in the tree:
The import process performs a number of validation steps to assure that the resource can be used inside k.LAB. In this case, the projection and other attributes are checked for conformance with accepted conventions and the shapes are validated. In general, k.LAB adapters are intentionally strict, and won’t accept files that are partially or badly specified: all information is needed in order for resources to be adaptable to all context of use.
2. The Resource Editor
k.Modeler features a Resource Editor that allows the user to manage supported resource types. When selecting a resource previously imported into the resources tree, the editor opens, showing three tabs, the default one being the Resource data tab:
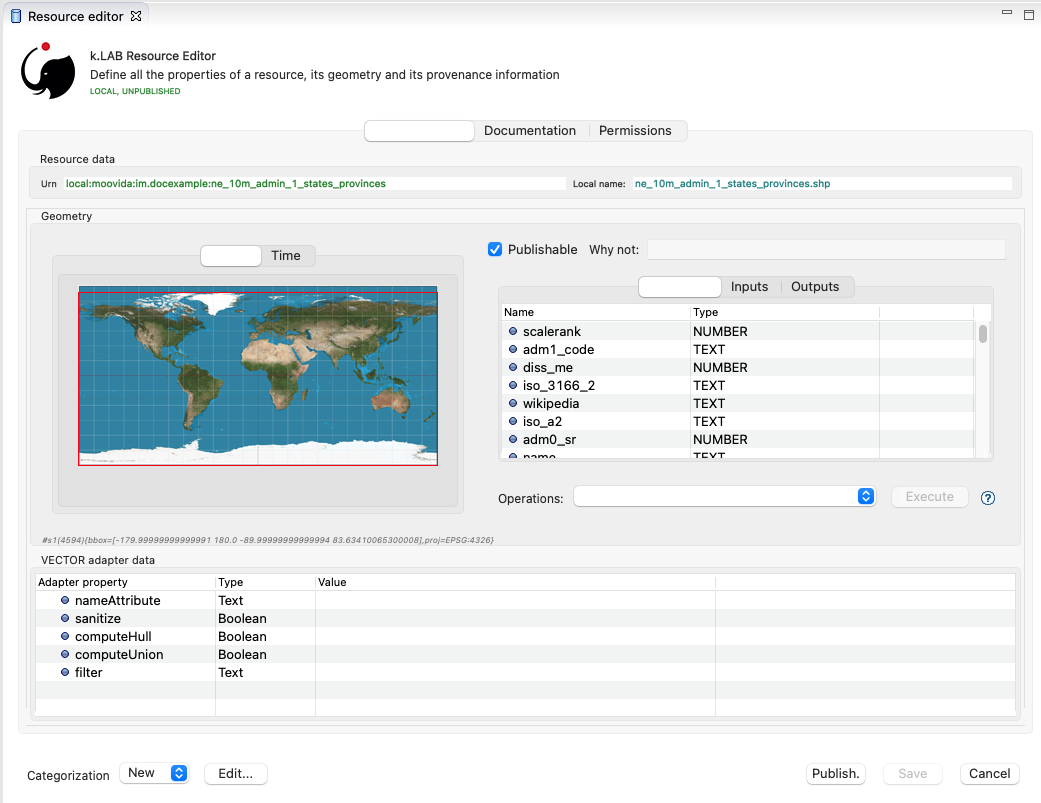
If the validation procedure had produced errors, the Publishable checkbox won’t be ticked and the Why not textfield will describe the reason.
|
Importing for example a multi-band imagery geotiff raster the same way as done with the shapefile, the editor reports an issue, and the URN is coloured red: 
It will be necessary to choose a band or provide a band mixer expression in the resource parameters to make the error go away and render the resource usable in a model. |
The editor exposes important information about the resource:
-
Its unique URN (Uniform Resource Name);
-
Its attributes, if any exist;
-
The geometry (space, time) and its textual encoding;
-
All adapter attributes that define how k.LAB will handle the resource.
Every resource also has a data type, which describes the main output. Because the type may change depending on the context of use, it is not shown in the editor. In the case of a shapefile the type is OBJECT, i.e. the resource, when applied to a context, will produce a set of objects, each of which will have its own independent geometry. In the case of a raster coverage, such as a geotiff or a WCS service, then the type would be NUMBER.
In the Java API, the possible types of a resource (also including many others that resources cannot produce) are defined in the Type enum which belongs to the IArtifact class. [1].
|
2.1. Local and public URNs
Each resource can be identified as local or public. Upon creation the resource lives in a user project, and is therefore local. Modelers wishing to use that resource must have that project loaded in their engine’s workspace. The name of a file-based local resource is derived from that of the original file: for example in case of a shapefile it is simply the file name without the path. The local name can be used as an identifier in place of the fully specified URN in k.IM models located the same project. The URN (which can be copied to che clipboard by right clicking on the resource through copy URN) is the fully specified identifier and is the recommended way to reference resources in k.IM namespaces.
A URN consists of 4 parts, separated by colons:
-
the node name (the name of the node where the resource was originally published);
-
the catalog (a logical space handled by the node, for example a domain such as hydrology, or a name describing a large-scale collection of data);
-
the namespace (a secondary logical space within the catalog);
-
the resource identifier.
Dot-separated paths are normally used for each component of a URN, providing a further way to organize and document the origin and logical scope of a resource, using reverse DNS notation when appropriate. A clean URN should contain only lowercase identifiers and no other characters than ASCII letters or the underscore sign, although other characters are accepted.
When a resource is created locally, the four parts of the URN are used differently:
-
instead of the node name, the string 'local' is used;
-
instead of the catalog, the URN will contain the user name of the user that created it;
-
instead of the namespace, the URN will contain the name of the project where the resource was created;
-
the identifier will be built from the file name (if file based) or from user input.
A local resource’s URN might for example look as follows:
local:moovida:im.docexample:ne_10m_admin_1_states_provinces
Once published, the URN of a resource will reflect the above described specification.
| One important note related to the node part in the URN: even if the resource will forever carry the originating node name in its URN, this doesn’t mean that it can’t be resolved by other nodes. k.LAB’s mirroring API can be used to mirror resources to different nodes, to maximize the chance that a public resource is resolved even if some nodes are offline, and to support load balancing in the k.LAB network for frequently used resources. |
There is a third type of resource, named universal resource (see the dedicated section) that, due to its nature, follows a particular URN schema, identified by the klab prefix. If the URN starts with the keyword klab, then the meaning of the 4 parts of the URN are the following:
-
the keyword klab;
-
the name of the adapter to use to resolve it;
-
the namespace to specify the service requested to the adapter;
-
the identifier of the specific resource.
For example, the following URN
klab:weather:stations:all
turns into a request to the weather adapter for the stations service, which returns weather station objects with their data, and requests all the stations in the context of resolution (as opposed to, e.g., only those of a certain category or technology). The weather adapter may be installed in the local engine (in which case no node is involved in satisfying the request) or provided by one or more nodes on the network. In the latter case, the node with the lightest load at the time of request will be chosen to honor it.
Detailed information about URN internals can be found in the section about URNs and resources management.
2.2. Attributes, inputs and outputs
Resources, when contextualized to a context through a model, always produce an output corresponding to their main type - for example numbers or objects. In addition to their main output, they may expose additional outputs (for example, a numeric resource may also produce, on request, an uncertainty metric related to the main output) and may, in the case of computed resources, need or accept inputs. In addition, resources that produce objects or wrap multi-dimensional data sources such as tables may expose attributes, which can be referenced in models.
As an example, a resource wrapping a vector spatial coverage (ESRI shapefile), which is of type OBJECT, has an attribute table:
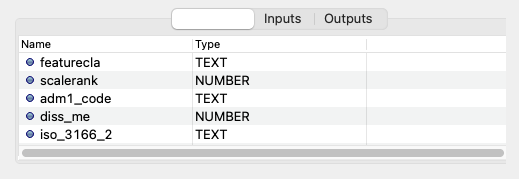
If the resource is a computation, it may have the inputs and outputs tabs filled instead, or in addition to, its attributes tab.
|
In a resource, the main output, along with optional attributes, inputs and outputs, are defined by a name and a data type, and make the connection between the resources and the semantic level. These are referenced in semantic models using their names to connect to concepts in the semantic world. |
The existence of attributes for an object resource allows it to be contextualized also as a "data" resource through a process called dereification. This corresponds to the removal of the object character by producing an attribute’s value as the main output, and simply using the objects' spatial and temporal geometry to distribute its value over the context of observation. So assuming that the shapefile in the example had a numeric attribute named population, containing the number of people living in each region, the URN local:moovida:im.docexample:ne_10m_admin_1_states_provinces#population can be used in a model that observes the population size over a grid without any other modification. The adapter will take care of rasterizing as needed. Depending on the adapter, parameters in the URN may be used to filter the data, modify them, or trigger sophisticated operations of different kinds.
2.3. The geometry
Each resource has a geometry, which describes the topology over which the resource’s information is distributed. A geometry may be trivial (scalar, describing a single value that does not change in time or space) but more typically contains dimensions, such as time and space. The geometry descriptor is normally initialized during the validation process when the resource is created, and may, under some circumstances, be edited by the user to add missing information.
Geometry data are summarized in an expression that is visible in the resource editor for inspection and cannot be modified directly. For the example shapefile it states:
#s2(4594){bbox=[-179.99999999999991 180.0 -89.99999999999994 83.63410065300008],proj=EPSG:4326}
The string, generated by the validator, can be read as follows:
-
The resource contains 4594 objects (defined by the presence of the pound character (#) denoting multiplicity of objects, and the number in parenthesis for the size of the resource in this dimension);
-
each object has irregular spatial bidimensional geometry (defined by the lowercase s2);
-
the spatial dimension has two attributes, shown between curly brackets:
-
a bounding box in projected coordinates;
-
a projection (Lat/Long)
-
Information in the resource string is also displayed in the temporal and spatial widgets in the resource editor, making it unnecessary to interpret the geometry string directly; for trained eyes, though, the string offers much information in a very short form and it can be useful to read it. The k.LAB Java API can manipulate the string definition and convert it to any internal representations needed.
The resource editor does not offer at the moment a way to edit the spatial geometry; a full-fledged time dimension editor is instead provided.
Dimensions may also be regular (for example a gridded raster will show S2, with an uppercase S indicating regularity in space) or generic (using Greek letters), meaning they imply a spatial dimension but do not indicate which one. Similar considerations as for space apply to time.
As shapefile sources contain no temporal information, the user can edit the temporal geometry using the time editor in the second tab of the geometry panel, which by default focuses on the space tab showing a world map.
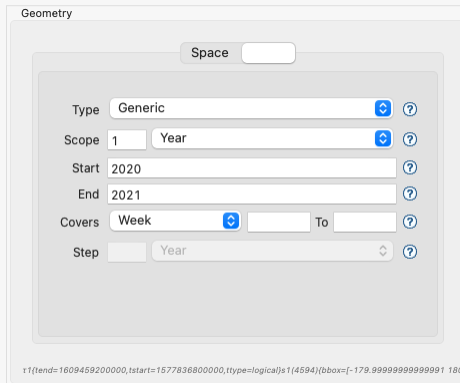
After that is done (for example to state that the spatial data refer to the year 2020 and should be considered unchanging over a year’s span) and the resource saved, the geometry shown will include the temporal information, for example:
τ1{tend=1609459200000,tstart=1577836800000,ttype=logical}s1(4594){bbox=[-179.99999999999991 180.0 -89.99999999999994 83.63410065300008],proj=EPSG:4326}
To show a slightly different example, this is what it might look like for a raster:
τ1{tend=978307200000,tscope=1.0,tstart=946684800000,ttype=logical,tunit=year}S2(4319,2159){...}
In this case, a raster grid of dimension (x = 4319, y=2159) has been annotated to refer generically to year 2000 (expressed in milliseconds after 1/1/1970): the data will also be used by k.LAB to make observations when contextualizing in a period beyond 2001, as long as there are no better sources of information for more recent years. A specific time extent (with a T instead of τ) would cause the resource to only be used within the time coverage specified.
2.4. Adapter parameters
The adapter is the software plug-in that takes care of validating, interpreting, encoding and decoding the original contents of a resource to adapt them to the k.LAB world. Each adapter has different functionalities and defines a set of parameters that control the way the resource is interpreted. Many of these parameters are filled in automatically when the resource is imported from a file; if instead the resource is created from scratch, the user will be requested to fill in the mandatory parameters before the resource can be created. The parameters remain available in the editor for modification: users cannot add arbitrary parameters, but the adapter will add an empty definition for all optional parameters so that they can be filled in later if desired.
The adapter properties view lists the name and parameters of the currently used adapter. In the discussed test case the used adapter is the VECTOR adapter:

The specific role of each parameter is discussed in the documentation of each individual adapter. As an example, the filter parameter seen in the picture can be used to exclude part of the resource, if necessary. The procedure is as simple as inserting a CQL (Common Query Language) based on the object’s attributes (ex. adm1_code=SOMECODE). Adapters that operate on more flexible resources (such as tables or machine-learned classifiers) can contain a high number of parameters, which are often organized hierarchially for ease of navigation.
Modifying parameters enables the "Save" button in the editor. Saving the resource triggers revalidation and will result in errors if the parameter values are incompatible with the functionality of the adapter.
2.5. Publishing a resource
Resources start their life as local within a user project, and can be used inside the project that contains them or in any other project that shares the same local workspace. While local resources may be enough to use them in k.LAB for a specific, short-term project, the natural lifecycle of a resource continues with publication, which makes it available across the k.LAB network. When published, resources become independent of projects, their URNs gain an "official" status following a linked data paradigm, and live on k.LAB Nodes which may optimize their data for faster serving and have them mirrored to other nodes for increased availability. While public resources may be visibile, at the choice of their owner, only to selected users or groups of users, their URLs are universally recognized and can be used in k.IM models without the need for any registration or download, as long as the user is connected to the k.LAB network.
The publish button in the k.LAB Resource Editor helps the user in the publishing process with a dedicated wizard:
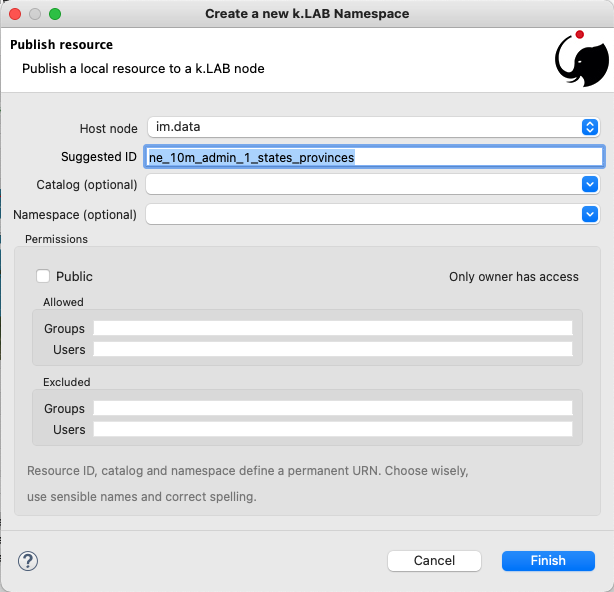
|
The publishing facilities in k.LAB are in active development, and many important details are yet to be defined. In general, a resource can only be published after a number of validation steps, including full metadata compliance and licensing information, validation at a stricter level than what requested for local usage, and conformity and uniqueness checks for the public URNs. Once published, a resource should not be changed, since changes in existing resources might break models that depend on them. Among the many details of the publishing workflow, k.LAB will eventually feature an optional peer review procedure (which will affect the prioritization of the resource when multiple alternatives are available) and a multi-criteria rating system. While the process is developed and tested with partners, it is important that users refrain from publishing resources unless directed by authoritative partners. |
The publishing dialog also allows fine granularity in the specification of resource permissions. By default a resource is visible only to the user that created it. The Public checkbox allows to make it globally visible. Finally, it is possible to make resources visible only to certain users and groups (comma separated list) or exclude groups/users.
| It is important to note that because resources are never used directly in k.LAB, but rather through semantic models, users will never see permission errors due to accessing resources that they have no rights to. Any model using a resource that is not allowed for the user running it is automatically deactivated and cannot be chosen to resolve its observable concept; the resolution process will automatically find a computational workflow that can resolve the query in terms of visible resources only. This enables a smooth and graceful enforcing of permissions. |
Before publishing, the metadata tab should be filled in with relevant metadata:
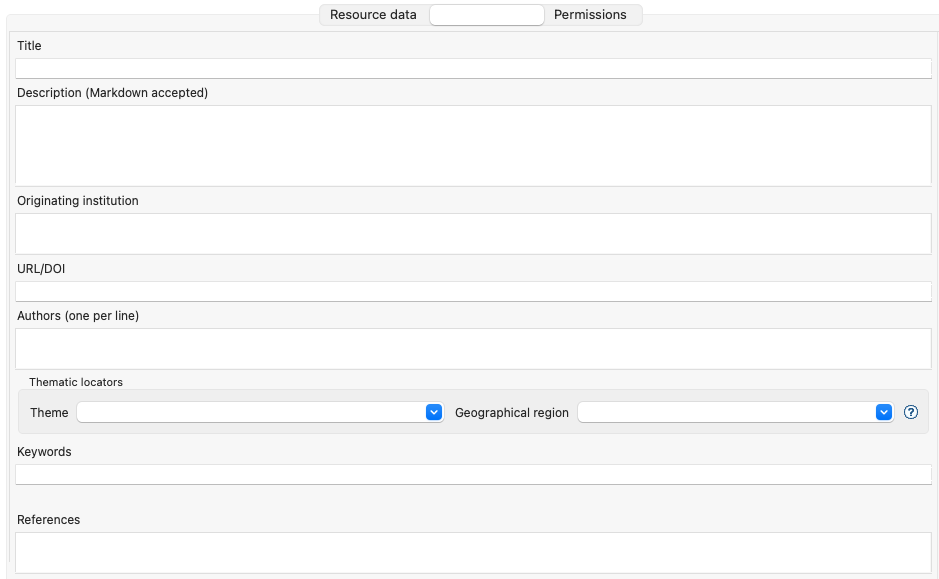
| Many users believe that information such as time and spatial context are part of the metadata. This is bad practice since they are part of the semantic and have their own place in k.LAB. |
2.6. Universal resources
In the section about URNs local and global URNs have been discussed and a third type of resource has been introduced: universal resources.
A universal resource is basically a service and does not own specific resource storage on the filesystem. Therefore universal resources can be considered public and do not need to be created. In fact, both nodes and engine may host universal adapters: when a universal resource is referenced, the engine will first try to contextualize it using its own installed adapters; only if the requested one is not available the engine will lookup nodes on the network that have it and allow it for the current user, then, if multiple ones are available, choose the node with the lightest current load and use the node resource API to obtain the data in the desired context. Universal resource adapters are created by implementing the IUrnAdapter interface, which does not have import, export and validation methods and thus has a simpler API than a full resource adapter. One example is the RandomAdapter[2] that is able to handle URNs that start with: klab:random:….
Any resource whose node name is klab: is a universal resource. This means that no physical node can be named klab.
The weather adapter[3] is an example of a complex service implemented as a universal resource. Because it relies on a large database of weather data and stations, updated regularly from online sources and contributing institutions, it can only be implemented as a service; behind the scenes, constant processing ensures data validation and synchronization of several datasources (ex. NOAA-catalogued weather stations) that change in time and are often integrated with new information. The underlying data are saved in an internal database and are made available through the URN to models that need weather data relative to a specific temporal and spatial geometry. The k.LAB weather resource can be accessed through the klab:weather:… prefix, where the catalog identifier specifies the weather service.
Universal klab resources can be served by different nodes the same way as it happens for other global resources. It is clear that while a random adapter resource - being very simple - can be run from any node, a weather adapter that would take days only to build the initial database will be accepted only on dedicated nodes. For that exacty reason only one node, im.weather, currently handles klab:weather resources.
2.7. Adding non file-based resources
In cases in which the resource is not file-based and a drag-and-drop action cannot be used, the new resource wizard can be launched by right clicking on the resources node and selecting the New resource… action. The wizard allows to define an id for the resource and select one of adapter types enabled for resource creation in the connected engine:
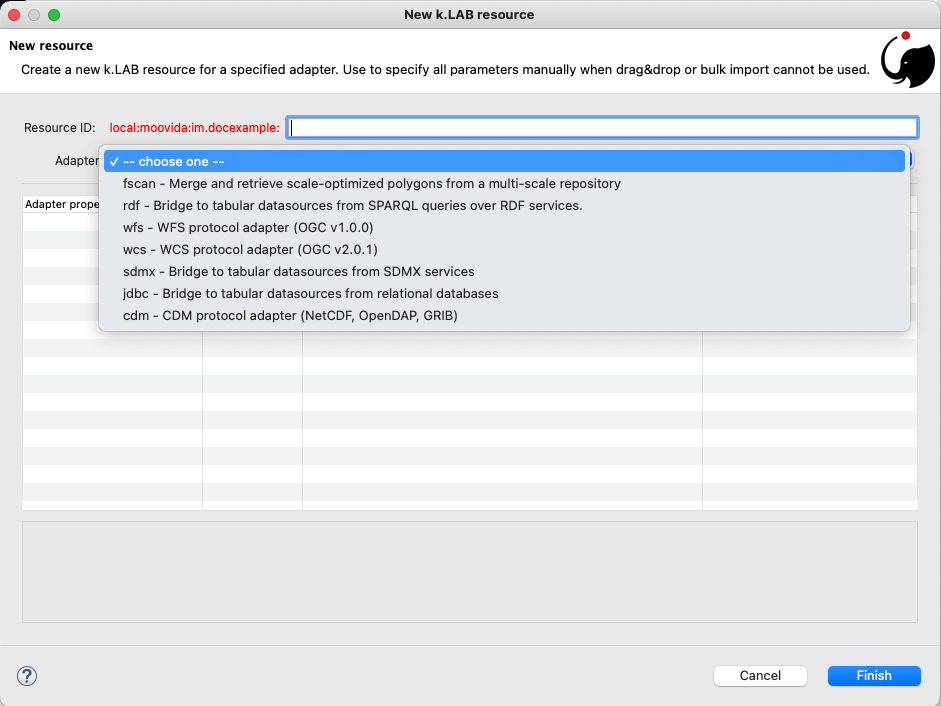
Once the adapter has been chosen, its parameters will appear, ready to be defined. The following image shows the example of the mandatory (red) and optional parameters of a WFS adapter:
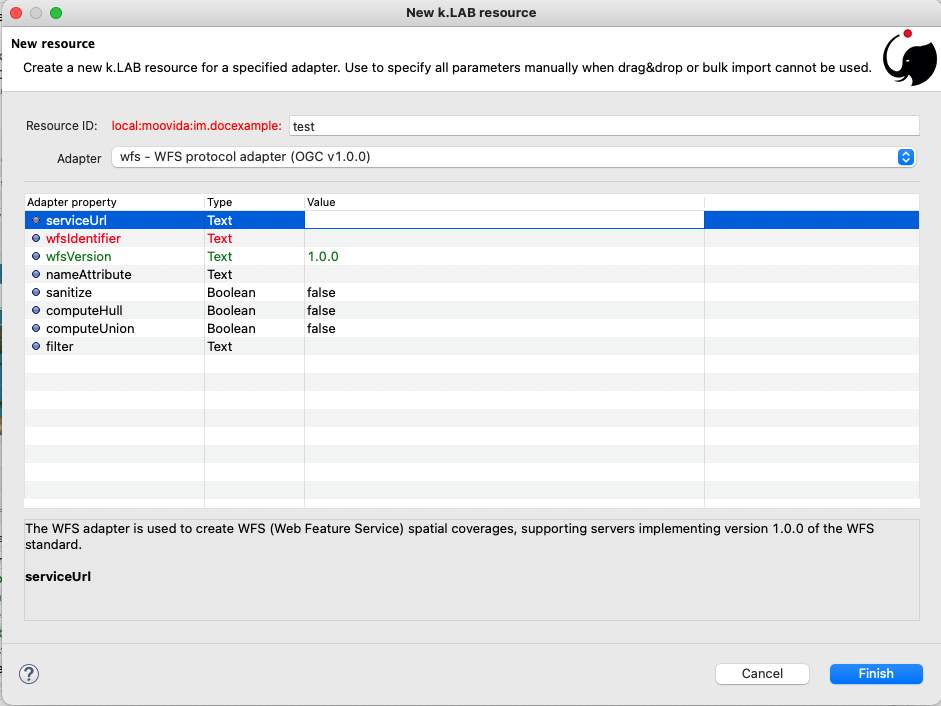
In the image it is quite clear what the URN of the new resource will look like (Resource ID at the top) and how for the local resource the user selects only the last piece of the URN, the resource identifier.
3. Local resources behind the scenes
Local resources are hosted on the local filesystem and belong to projects. The way things are handled behind the scenes can be understood when leaving the safety of the k.LAB perspective by switching to the Project Explorer perspective:
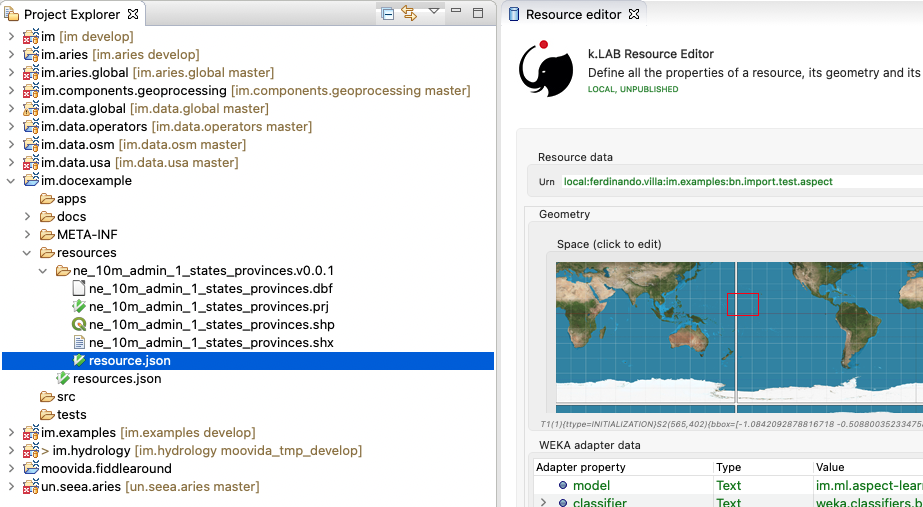
While the k.LAB prespective shows a logical view of the resources, the Project Explorer presents a physical view of the resources, as they are persisted on the storage. The average user does not need to know the details of how resources are stored, but this information can help more advanced users understand resources and report problems.
| File-based resources are copied to the resources folder when imported, being it few bytes or many gigabytes, to ensure the self-consistency of the resulting resource. The user should be aware of ramifications when importing datasets and when committing projects that contain resources to git or other source code control system. |
Looking into the resources folder we will find a folder for each created resource. Each resource also presents a resource.json file, which contains all information k.LAB needs to know about. The json file is text-based and indented for readability, so the basic information from it is easily accessible in the k.LAB Resource Editor user interface:
{
"urn" : "local:moovida:im.docexample:ne_10m_admin_1_states_provinces",
"version" : "0.0.1",
"adapterType" : "vector",
"localPath" : "im.docexample/resources/ne_10m_admin_1_states_provinces.v0.0.1",
"geometry" : "#s2(4594){bbox=[-179.99999999999991 180.0 -89.99999999999994 83.63410065300008],proj=EPSG:4326}",
"projectName" : "im.docexample",
"localName" : "ne_10m_admin_1_states_provinces.shp",
"type" : "OBJECT",
"resourceTimestamp" : 1613125478144,
"metadata" : {
"im:keywords" : "features,ne_10m_admin_1_states_provinces",
"dc:title" : "ne_10m_admin_1_states_provinces"
},
"parameters" : { },
"localPaths" : [ "im.docexample/resources/ne_10m_admin_1_states_provinces.v0.0.1/ne_10m_admin_1_states_provinces.shx", "im.docexample/resources/ne_10m_admin_1_states_provinces.v0.0.1/ne_10m_admin_1_states_provinces.dbf", "im.docexample/resources/ne_10m_admin_1_states_provinces.v0.0.1/ne_10m_admin_1_states_provinces.prj", "im.docexample/resources/ne_10m_admin_1_states_provinces.v0.0.1/ne_10m_admin_1_states_provinces.shp" ],
"history" : [ ],
"notifications" : [ ],
"attributes" : [ {
"name" : "featurecla",
"type" : "TEXT",
"key" : false,
"optional" : true,
"exampleValue" : null,
"index" : 0
},
...
...
...
{
"name" : "ne_id",
"type" : "NUMBER",
"key" : false,
"optional" : true,
"exampleValue" : null,
"index" : 0
} ],
"spatialExtent" : {
"east" : 180.0,
"west" : -179.99999999999991,
"north" : 83.63410065300008,
"south" : -89.99999999999994,
"gridResolution" : null,
"gridUnit" : null
},
"dependencies" : null,
"outputs" : null,
"exportFormats" : {
"shp" : "ESRI shapefile"
}
}4. Finding resources
To help users find resources when writing models, the k.Modeler offers a resources finder view:
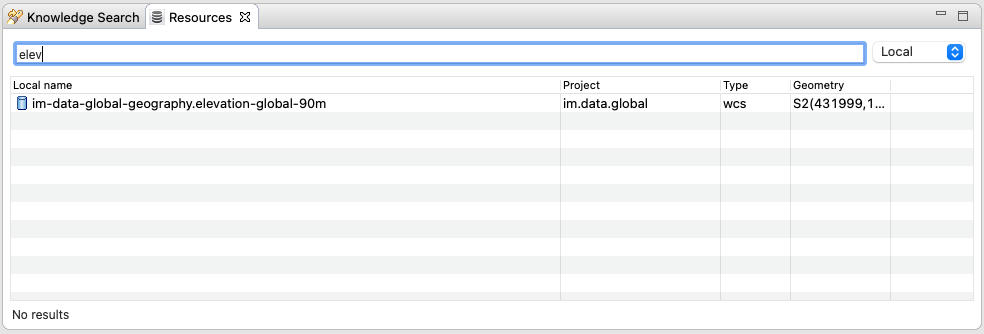
On entering keywords in the search field, the view presents resouces whose URN matches the text.
On double clicking on the resource, it is opened in the k.LAB Resource Editor while with a right click it is possible to copy the URN to the clipboard, to use in k.IM models. The "Copy URN" action is also available in the k.LAB Explorer in the right-click menu, along with operations to delete the resource or move it to another project.
The upper right combobox allows to set the filter on looking for the resource locally or on public nodes. When set to public, search is expected to operate not only on URNs, but also on metadata, descriptions and other information saved with the resources. The public view will also display status information on resources that are published from the local environment, allowing the user to list the resources published (including when publishing failed) and, if wished, remove from the nodes they are published to.
| At the moment the search API for nodes is not implemented, therefore the public search is not yet usable; the publishing feedback features are partially implemented and should not be relied upon. |
5. The developer perspective
The following sections describe a Java developer’s perspective on what has been seen in the previous ones. Notable code passages are used to explain the information flow and processes behind the k.LAB Engine and k.Modeler.
5.1. URNs
Simple textual information on URNs is handled in the singleton Urns[4]. The class is a utility class that allows the developer to manage URNs. In addition to the methods in the Urns class, a string-based URN can be used to create a org.integratedmodelling.klab.Urn object which also gives access to URN parameters and is nicer to handle than a simple string.
In k.LAB we consider a URN any string identifier that can be connected to known objects in the k.LAB ecosystem. So while a resource URN typically displays the structure discussed here, other objects such as concepts (e.g. geography:Slope), concept expressions (im:Normalized geography:Elevation) or model identifier (im.data.global.dem90) may also be referred to as URNs. All these can be considered short-hand forms that can, if needed, be expanded into a fully compliant URN form, including a common urn:klab: prefix. We do not normally need to do so when writing and discussing resources or models, nor when writing code using k.IM or k.Actors. The full URN may be important for standardization in API communication.
|
One important information developers should be aware of, is the one expressed by the first attributes of the class:
final public static String KLAB_URN_PREFIX = "urn:klab:";
final public static String LOCAL_URN_PREFIX = "urn:klab:local:";
final public static String VOID_URN_PREFIX = "urn:klab:void:";
final public static String LOCAL_FILE_PREFIX = "file:";Another information that the URN class (in conjunction with the Resources class, explained later) makes clear are the tree levels of URN visibility:
-
local
-
global
-
universal
5.2. Resolving URNs to resources
URN resolution is handled inside the singleton Resources[5].
While the instance of Resources can be accessed directly, it is a service (IResourceService) and as such it can be accessed throughout the system also from components that do not have directly imported the package of the implementation.
IResourceService service = Services.INSTANCE.getService(IResourceService.class)Resource resolution is done by passing the URN to the resolveResource method. If the URN can be properly resolved, either locally or globally, an IResource object is returned.
5.3. IResources
In the IResource interface we find various methods, whose functionality can be tracked back to the k.LAB Resource Editor user interface (this should now sound obvious, since it represents the resource object). No API in the current version of k.LAB can yet be considered stable and the details shown here may change. The methods are quite self-explanatory and are documented in Javadoc. Some of these are worth describing for better understanding without the need to access the source code:
-
getDependencies(): resources can depend on other resources. If that is the case, the method will return a list of the URNs of said dependencies.
-
getGeometry(): the resource’s geometry. Geometries are quite complex in k.LAB and can cover different extents (also time, not just space) and have different dimensions. Interested developers should head to the javadoc of the IGeometry interface to dive in the internals of geometries. It is important to understand that the scale (IScale[6]) is the semantic version of the geometry. As such it is possible to create a scale from a geometry or vice versa. It is in the scale where the geometry finds a place in which space and time are understood through semantics, while at mere IGeometry level it represents a topologhy and that’s it.
-
getVersion(): each resource has a versioning system. Local resources don’t obey to said system. But once a resource is published, a version 0.0.1 is attributed to it. At every change a version update is done.
-
getHistory(): each resource also contains a list of its history. The list contains all resources the current resource transitioned through in history, each with its own version.
-
getParameters(): a resource can have parameters. Part of them can be created by the adapter that took care of a resource (the ones seen in section about adapter parameters).
-
getAttributes(), getInputs(), getOutputs(): resources that produce objects can have a set of attributes, modeling resources can have inputs and outputs. These are visualized in the k.LAB Resource Editor as shown in the attributes section.
-
getAdapterType(): the adapter type that is in charge of the resource.
It is important to note that resource objects are mandatorily created using the resource builder[7].
5.4. The resource adapter
Once a resource is imported into k.Modeler (for example dragging a file onto the resources node) the importResource method ot the resource service is called.
The first step in there is the choice of the adapter (IResourceAdapter) that can handle the resource:
IResourceAdapter adapter = null;
if (adapterType == null) {
List<IResourceAdapter> adapters = getResourceAdapter(file, parameters);
if (adapters.size() > 0) {
adapter = adapters.get(0);
adapterType = adapter.getName();
}
} else {
adapter = resourceAdapters.get(adapterType).adapter;
}Once the adapter is defined, a set of tooling objects are made available through its API: a validator, an encoder, a publisher. To create a new resource adapter it is necessary to create an object that implements the IResourceAdapter interface but also its subobjects, as IResourceValidator, IResourcePublisher and IResourceEncoder.
The adapters are discovered by the system from their annotation (ex. in the raster adapter):
@ResourceAdapter(type = "raster", version = Version.CURRENT,
requires = { "fileUrl" },
optional = { "band", "interpolation", "nodata", "bandmixer" },
canCreateEmpty = false, handlesFiles = true)
public class RasterAdapter implements IResourceAdapter {
// ...
}The IResourceValidator interface guides the developer in the implementation of the main validator functionalities:
-
canHandle: the first and fastest check that defines if the adapted is able to handle the given resource.
-
validate: implements the validation logic starting from a URL and userdata. Successfull validation results in returning a builder object used to then create the resource.
-
update: a method that allows the resource to be saved as the result of user changes
-
performOperation: if the resource allows to perform operations on the resource, it should be implemented. Operations are then made available to the user in the k.LAB Resource Editor in the combobox below the attributes table.
The RasterValidator class is a good startig point for developers that want to understand how the resource is created using the builder object. In the validate methods it is simple to track how spatial extent is defined, the projection is set or for example the geometry is defined:
Geometry geometry = Geometry.create("S2")
.withBoundingBox(
envelope.getMinimum(0),
envelope.getMaximum(0),
envelope.getMinimum(1),
envelope.getMaximum(1)
)
.withProjection(crsCode)
.withSpatialShape(
(long) grid.getGridRange().getSpan(0),
(long) grid.getGridRange().getSpan(1)
);
builderObj.withGeometry(geometry);5.5. Contextualizing a resource
When a resource need to be contextualized, the getResourceData method of the Resources class is used.
There are various versions of the method that allow to iterate over the resource using a given scale (i.e. defined steps in sapce and time) or to simply iterate over the whole resource without a particular notion of scale.
|
At the current time the IResourceService doesn’t provide the getResourceData methods, but might soon do that to expose them also in the service object. This can be particularly useful for components that do not have access to the engine, but need to validate other resources they concurr with. |
The first step towards contextualization is to check whether the resource is local, global or universal.
After a first simple URN check the resource is investigated on being local, global or universal (in which case it could still be local, since the universal resource could reside on the local node):
boolean local = Urns.INSTANCE.isLocal(resource.getUrn());
...
if (urn.isUniversal()) {
local = getUrnAdapter(urn.getCatalog()) != null;
}If it is local but also universal, then the adapter is retrieved directly from the catalog and used to build the data object (IKlabData):
IUrnAdapter adapter = getUrnAdapter(urn.getCatalog());
...
IKlabData.Builder builder = new LocalDataBuilder((IRuntimeScope) context);
...
adapter.getEncodedData(urn, builder, geometry, context);
IKlabData ret = builder.build();If the resource is not local, then the workflow is uniform for global and universal resources, starting by finding the node, choosing the one with less load between the ones available. Then a REST request is prepared and sent to the node using a builder that creates the data that are retrieved from the resource:
INodeIdentity node = Network.INSTANCE.getNodeForResource(urn);
...
DecodingDataBuilder builder = new DecodingDataBuilder(
node.getClient().post(API.NODE.RESOURCE.CONTEXTUALIZE, request, Map.class), context);
IKlabData ret = builder.build();Generally speaking, if the resource is local, a LocalDataBuilder is used at the client side, and passed to the encoder of the adapter. The encoder is the component that takes the resource and the scale and fills in all the necessary pieces of the data builder:
IResourceAdapter adapter = getResourceAdapter(resource.getAdapterType());
...
IKlabData.Builder builder = new LocalDataBuilder(context);
adapter.getEncoder().getEncodedData(resource, urnParameters, geometry, builder, context);
IKlabData ret = builder.build();|
A DEEPER LOOK Take the case of a raster resource. Contextualizing it would make the encoder take the geometry, maybe create a subset of it, reproject and apply any necessary transform and finally then it would extract each x/y cell and pass them to the builder. This is how a builder manipulates a resources. Depending on the presence of a context, once the build method is called a semantic or non-semantic artifact can be created. As specified, in the semantic case the builder is with context, where the context needs to be pre-existing and empty, i.e. ready to be filled. The build process creates a semantic artifact as for example an object of type: IState, IDirectObservation, IObservationGroup. The most common method in k.LAB is the semantic contextualization. But non-semantic artifact building exist for special purposes as for example when resources have to be used from inside a specialized process that does not need to participate in the semantic resolution. One example is the table adapter, that can use a secondary resource to spatialize the contents. In that case no semantic contect is used for contextualization, a pure spatial topology is enough. And the result is known to be non-semantic. For example objects of type: IDataArtifact, IObjectArtifact |
If instead the resource is public (hosted on an external node), a DecodingDataBuilder is used at the requesting engine side. It follows the same logic as the local builder, but using network protocols to retrieve the necessary pieces (using protobuf for the deserialization).
DecodingDataBuilder builder = new DecodingDataBuilder(
node.getClient().post(API.NODE.RESOURCE.CONTEXTUALIZE, request, Map.class), context);
IKlabData ret = builder.build();At the node side, where public resources reside, a specialized EncodingDataBuilder is used to serialize the built result into the Protobuf message which will be sent to the requesting engine. The engine will use the DecodingDataBuilder to decode the message and pass the result to the contextualizing dataflow. This logical arrangement allows the same resource adapters to function in engines and in nodes without modification: adapters may, however, adopt specialized interfaces that will enable optimization functions to be run only in nodes, so that resources can be optimized for fast delivery when they are exposed through public APIs.